TLDR: Yes, here’s how
Every code commit or merge is one of the critical decision points that determine whether you're helping or hindering progress. Getting it right is the difference between your customers cheering or crying over your next deploy.
How do we determine whether it’s time to commit?
- Testing
- Code Reviews
- A hunch on the unknown risk?
The hunch is crucial, years of getting it wrong helps build an intuition for the level of risk in the unknown unknowns and whether that risk is acceptable. But our otherwise sound intuition is easily derailed: tiredness, pressure, mood, frustration, recent success or failures or just plain joy at getting a tricky bit of code apparently working, all have an effect. “The emotional tail wags the rational dog.”
So what if we took a more data driven approach to this crucial decision? What factors should we consider and how can we measure them?
- The developer - Historically what are the odds that a developer will have a bug in their code
- The size of the change - The more code changed the more likely a bug has been introduced
- The complexity of the change - Some types of code are much more likely to contain bugs than others. We can classify types of code and factor these into our calculation.
- The quality of the repository - However solid your code is, if it’s sitting on shaky foundations it’s much harder to make a change without causing undesirable side effects. We can measure this by the ratio of fixes made in a commit history.
Developing a formula for this is complex, the impact of each factor will vary for each repo, and the factors influence each other. Luckily this is the kind of problem that machine learning excels at. At SoLittleCode we’ve been working on this problem for the last year and are now able to calculate probabilities of a bug in a commit with around 70% accuracy.
Once you know the probability of a bug in your code what should you do about it? With a model capable of calculating the probability of a bug with any developer on the team committing that code, we can calculate whose review is most likely to find the issue. The following screenshot is what our tool adds to a PR when I try to make a change to a fork of Angular.
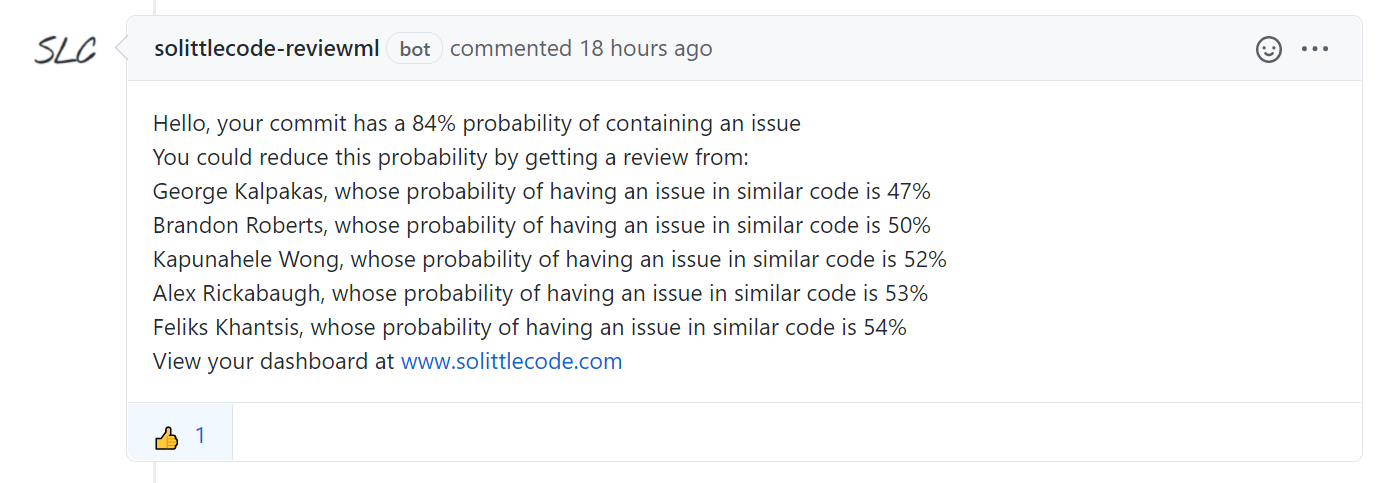 I guess I’m not quite ready to start coding for Google!
I guess I’m not quite ready to start coding for Google!
If you’d like to discuss other ways of using this technology please let me know.